
The TechBio Idea Maze: to be, or not to be, an AI-native Biotech?
Finding a path to TechBio success through the fog

So you want to start a TechBio company, but where do you start?
One way to approach this is by exploring the idea maze. As discussed in my previous post, the idea maze is a useful decision-making construct, not because it will chart out the entire future of your startup, but because it will help you see the path dependence to certain decisions that (TechBio) startups have made and a comprehensive view of the playing field. Path dependence is particularly pronounced in TechBio and other deep tech areas because it is hard to pivot from some initially chosen paths. In this post I will be going for breadth, not depth, in the coverage of the idea maze.
Do all paths lead to starting a full-stack or AI-native biotech, a biotech company where AI and/or software is central to their operations? Some do, but many do not.
Entering the idea maze
The first question is are you solving for human health problems or other biology problems (sustainability/climate, synbio/chemicals, animal health, plant science, etc.). In this post I’m going to focus on human health problems, though I may save a future post for paths solving for other biology problems.

The next question is are you trying to solve the problems of the people who are either discovering, developing and commercializing drugs (biotechs/pharma), OR who have various medical maladies (patients).
Let’s say you want to solve the problems of biotechs/pharma, then which branch(es) are you helping with: discovery, development or commercial?

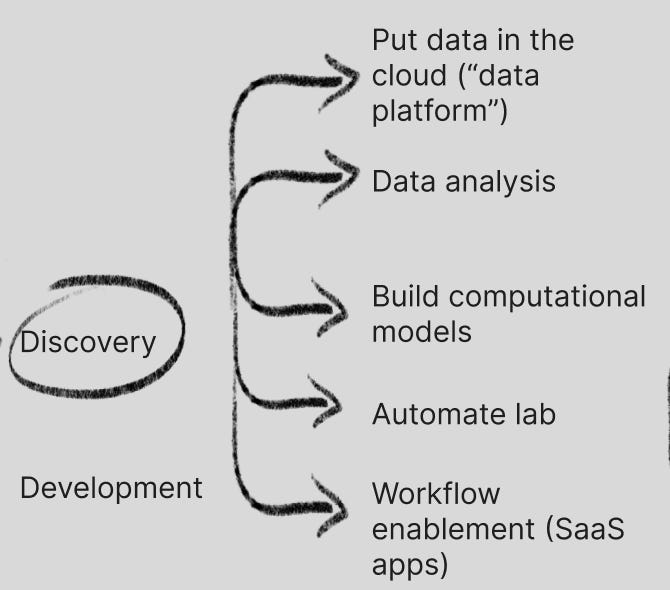
Discovery
Discovery (pre-clinical research) has been the early focus of TechBio, so let’s start there. TechBio companies in Discovery are largely solving for scientist workflows across putting data in the cloud (“data platform”), data analysis tools, computational models, lab automation and workflow enablement among other areas.
Discovery: data in the cloud
TechBio to date has largely focused on helping R&D teams put data in the cloud for better standardization / interoperability of data (“data platform”). Biopharma has largely used standard cloud providers and more specialized ones like Databricks, but also Benchling and Dotmatics (fka Insightful Science), 2 leaders in the biology R&D cloud and SaaS space. Dotmatics was a pioneer in the space in 2005, and Benchling helped to create a new TechBio narrative in 2012.
How big is the opportunity for this stop on the idea maze? Dotmatics has a bit of a lead in revenue traction ($200M+ EoY 2023 for Dotmatics, $210M ARR for Benchling in May 2024), but Benchling leads in overall usage (est. ~400K monthly active users [MAUs] for Benchling, ~300K MAUs for Dotmatics) and likely is growing at a faster rate. While usage is not a perfect proxy to revenue, it is the closest I can get to estimation of value without known revenue of private companies.


Discovery: data analysis
Newer startups like LatchBio (2021), Mantle Bio (2023) and Sphinx Bio (2022) have tried to serve more niche needs like no code data analysis, data/model hosting and more. It is still early, Latch has a minor lead in this niche, however, no amount of hustle 6-days a week in office culture can overcome the local maxima they are stuck in without the tailwinds of product/market fit and growth in industry adoption trends. It is hard to say how big this idea maze niche is, as growth will likely not be exponential and pricing tends to be on a storage and compute (CPU, GPU) basis. These startups are more computational biologist workflow-compatible UI layers on top of cloud compute and storage.
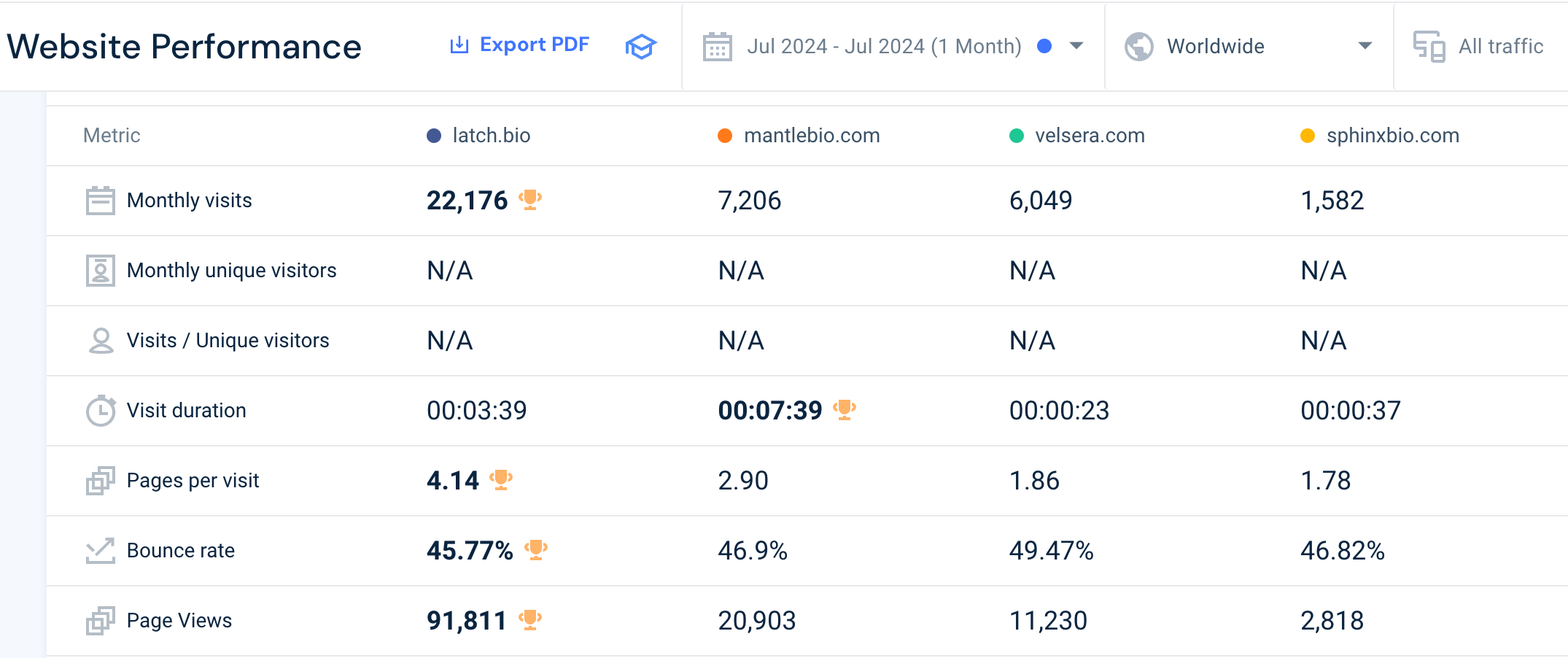
Discovery: computational models
Another stop in the idea maze is computational models, which is a broad term I used for a variety of techniques to improve drug design and discovery including physics, AI/ML and other simulation techniques. Computational models can reduce the time spent in discovery by focusing resources on more effective paths to test and validate in the wet lab and in animals, and/or completely eliminate many of these steps to get to an investigational new drug candidate (IND) to be advanced to clinical trials with a higher rate of success than traditional methods.
There is a lot of venture capital being plowed into this part of the idea maze ($10B from 2019-2023, and quite a bit in 2024 as well) with the hopes of significant growth, however the monetizable size of this opportunity on the idea maze is still relatively small even decades in with not fully computationally designed drug approved by the FDA yet.
Schrödinger is a pioneer in drug design computational models (largely physics based) has grown software revenue by 2.7x in the last 5 years and has been in business for 30+ years, but still is hovering around $160M SaaS/software revenue, which is still smaller than what Benchling and Dotmatics have achieved.

Schrödinger has diversified over the years into drug discovery revenue, largely partnerships with pharma to advance candidates discovered and designed with Schrödinger’s platform to clinical trials, with revenue mostly in the form of royalty/milestone payments. So far the most successful financial outcome has been tied to its joint venture with Atlas Venture called Nimbus Therapeutics leading to the sale of 2 assets, most recently a TYK2 inhibitor drug treating psoriasis that passed phase 2 trials with flying colors, has the potential to be a best-in-class competitor to BMS’s Sotyktu (estimated by Leerink Partners to achieve peak sales of $832M in 2030), and was acquired by Takeda for $4B in cash. Schrödinger received ~$147M in cash proceeds based on its ~3.7% equity position in the Nimbus owned entity that developed the TYK2 drug.

This “drug discovery revenue” category serves as an interesting model that many deep learning and generative biology (protein) model developers have taken as their primary revenue model including Atomwise, Recursion, Exscientia (acquired by Recursion), and others.
These companies are full stack AI(computational)-native biotechs, incorporating model development into the foundation of company formation and advancing drug candidates through clinical trial development, largely in partnership with larger pharma companies (Sanofi, BMS, AstraZeneca, among others). The partnership model typically consists of an upfront cash payment for the collaboration on a specific candidate, and milestone payments based on clinical readouts and approvals. Recursion is probably one of the furthest along in the full stack AI-native biotech space, with a relatively healthy balance sheet and runway through 2027 allowing for multiple shots on goal to get an approved drug(s).
Proprietary data generation is a key advantage that Recursion has promoted, and claims to be one of their primary non-drug assets (and moat). This is where the idea maze gets really complicated, we start to jump around different strategies to build the components of a full-stack AI-native biotech including automation of labs (robotics) to drive data generation and model creation to design better drugs:
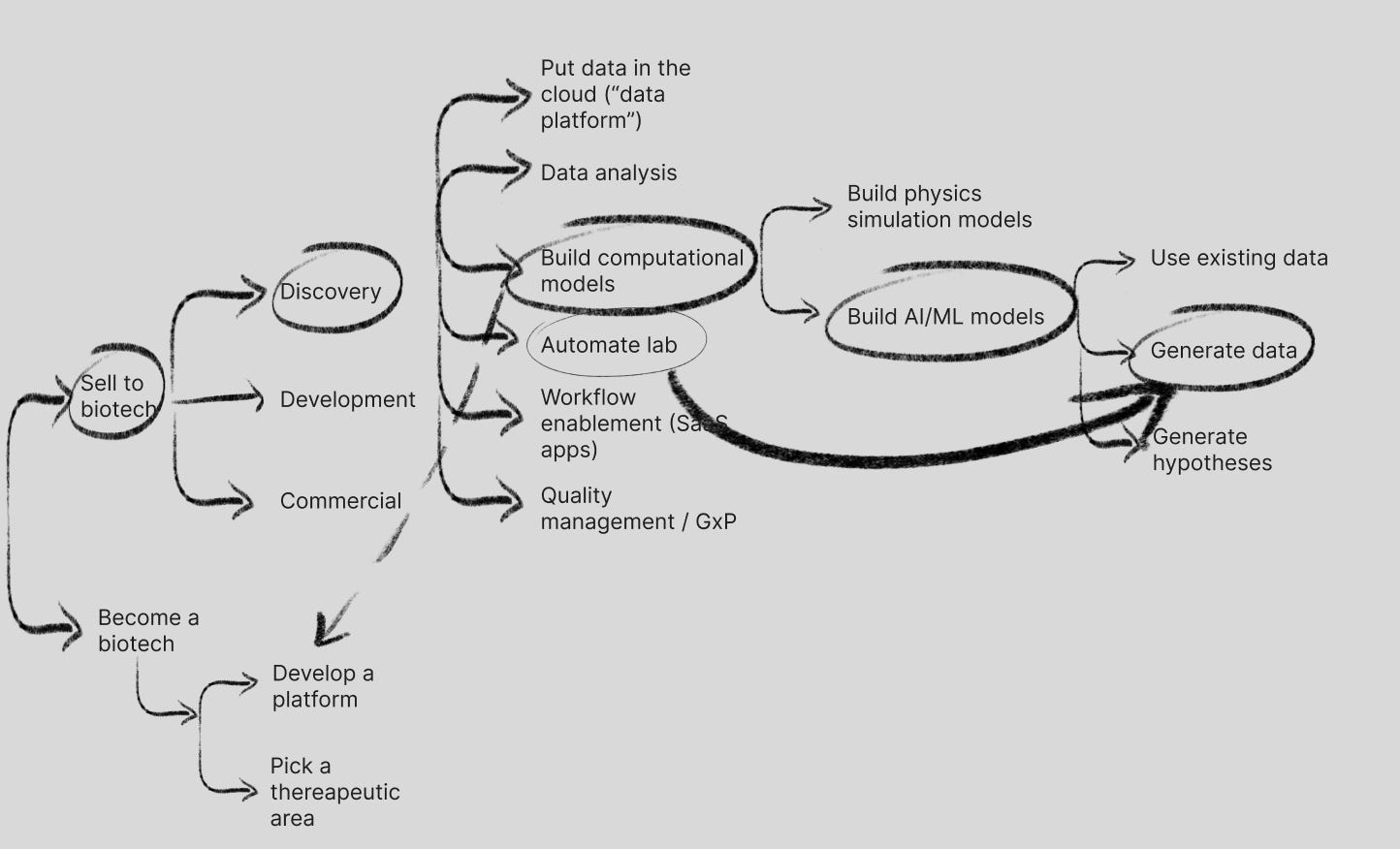
Recursion CEO Chris Gibson laying out the vision in Download Day 2024
Recursion has taken a strategy of proprietary data generation at scale along with selective M&A, especially in the last 12 months taking advantage of high interest rate environments to pick up valuable assets (Exscientia, Valence Labs, Cyclica). Exscientia provides 3 development candidates, extra cash + milestone payments, and data. Valence Labs is largely a top-of-funnel generation engine for scientist attention (LOWE drug discovery workflow SaaS tools, Valence Labs Portal community of computational biologists) and data acquisition (Polaris for data acquisition and benchmarks). Recursion is the embodiment of the TechBio full stack AI-native company.

There are more TechBio startups following Recursion’s primary strategy of scaled data generation to feed AI/ML models, including Leash Bio (founded by ex-Recursion employees), Kimia Therapeutics (spun out of recently acquired GLP-1 maker Carmot), and BigHat Bio among others.
Full-stack AI-native biotech companies can be valued at a premium compared to normal biotech companies if they can generate drugs at a lower CapEx and OpEx, generating a higher ROI than current methods of drug R&D. Can AI change the business model of drug R&D to reduce the need for huge CapEx in search of an ever elusive approved drug?
Flagship Pioneering, the large scale biotech venture incubator, is trying to change the business model with AI and has spun up several entities in the AI x Bio space including Valo and Generate Biomedicines. Flagship’s most successful incubation to date, Moderna, has used AI/ML for everything from its COVID-19 vaccine development to assessing future candidates in the oncology space. Generate Biomedicines is using generative AI technology to come up with new protein drug candidates across life sciences first, and across other industry applications later. A recent Data in Biotech podcast episode with Generate Biomedicines CEO Mike Nally is worth a listen (below) for more on their approach. It is hard to tell what revenue opportunities there are outside of standard drug development, though we have some early signs from Absci that the pickup may not be that great yet given relatively stagnant TTM revenue of ~$5M for the last few years despite all the hype around generative antibody technology.
There are other approaches beyond AI/ML and physics based modeling, as focused research organization (FROs) FutureHouse is taking the bet that better hypothesis generation is the key to AI scientists, not huge amounts of data, but ground many of its initial open source tool LLM-derived answers on actual research. See below for a talk by FutureHouse CEO Sam Rodriques at the excellent BioML lecture series at Berkeley:
EvolutionaryScale (generative AI for proteins, trained on a massive library of naturally occurring proteins), Isomorphic Labs (Google DeepMind incubated, and creators of AlphaFold) and Xaira (built with RFDiffusion from David Baker’s lab) are all large bets in the AI drug discovery space. There are many approaches and dozens of AI designed/discovered drug candidates in clinical development, however none have crossed the finish line to FDA approval yet. The computational and AI drug discovery space is crowded, but will likely consolidate over the next 1-2 years.
Development: Clinical Trials and Manufacturing
Going back upstream on the idea maze we navigate to development: the testing of a drug candidate through clinical trials for safety and efficacy, and the manufacture of the drugs used in these trials and eventually at commercial scale.

There are many clear levers for TechBio in clinical trials, including some similar themes to discovery, and less apparent levers in manufacturing:
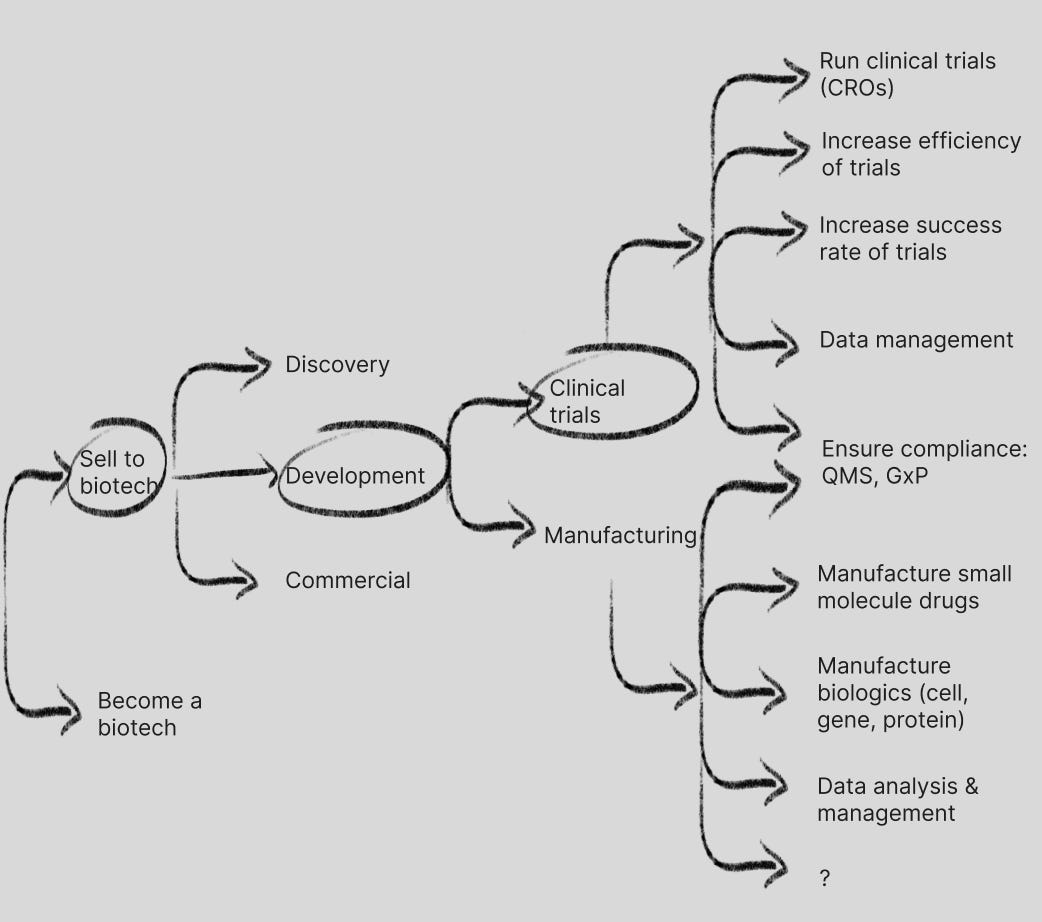
Clinical trials: running clinical trials, increasing efficiency and success rates
Actually running clinical trials is probably the biggest revenue driver, with giants like Thermo Fisher Scientific, IQVIA, Labcorp and others serving as outsourced clinical trial organizations or contract research organizations (CROs). Recent US national security (IP stealing + sharing with CCP) concerns will re-shore research work conducted by WuXi AppTec and other Chinese based CROs to the US, but full transition is not required until 2032.
Vial is nipping at the heels of these CRO incumbents by trying to reduce the cost and increase the speed of running clinical trials. If you change the economics of the per patient cost for these trials, then you can potentially run more trials and have more opportunities to get a drug candidate approved. The efficient CRO capability also offers an interesting pivot point for Vial to become a full-stack AI-native biotech, as it has incubated an AI drug design & discovery arm called BatteryBio and is aiming to advance 1,000+ drug candidates into clinical trials in the coming years (see Elliot Hershberg’s excellent overview of Vial here). In the idea maze it is combining elements from development and discovery to build a full-stack AI-native biotech.

Formation Bio (fka TrialSpark) is taking another approach to creating a clinical development first AI-native biotech: build a proprietary clinical trial platform to speed up patient recruitment, streamline site management and data collection/analysis, but acquire clinical stage assets that have some vetting (phase 1 / IND, etc.) and move them through their platform more successfully and cost effectively. This narrative and progress to date has landed Formation a partnership with AI-hungry valuation stagnant Sanofi, and OpenAI. Formation has effectively turned its clinical trial platform along with acquisition of assets into a new strategy on the idea maze to form an AI-native biotech, without a reliance on computational drug discovery models:
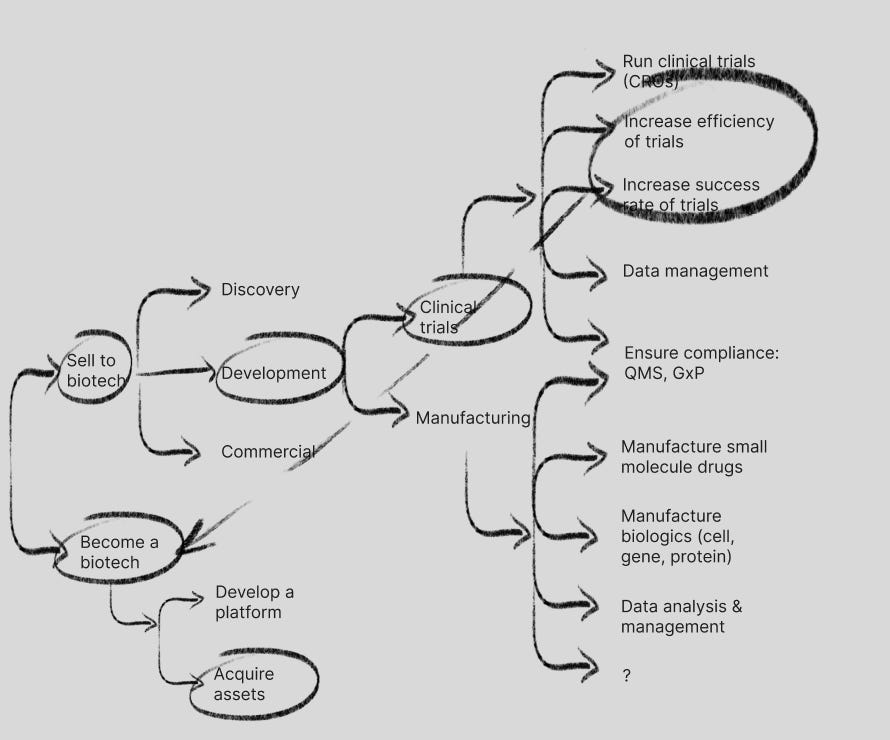
The development stage is also the place where hub-and-spoke companies like Roivant, BridgeBio and (to some degree) Nimbus shine. They are effectively holdcos following Andrew Lo’s portfolio optimization playbook to acquire clinical stage assets, spin up newco entities around them with recruited management teams, and attempt to advance these assets to the point where the newcos can be sold for a markup via M&A or via IPOs. This has worked well so far for shareholders, though requires much more up front capital. Roivant has used its cash pile and revenue to help fund acquisition of computational model development companies like Psivant, focused on physics modeling, from a $450M acquisition of Silicon Therapeutics, and incubations like Vant AI, with a focus on protein interaction models and protein degrader collaborations, and Datavant, with a focus on real world data linkage (discussed in the Commercial section of this post), and the idea maze starts to get real messy:
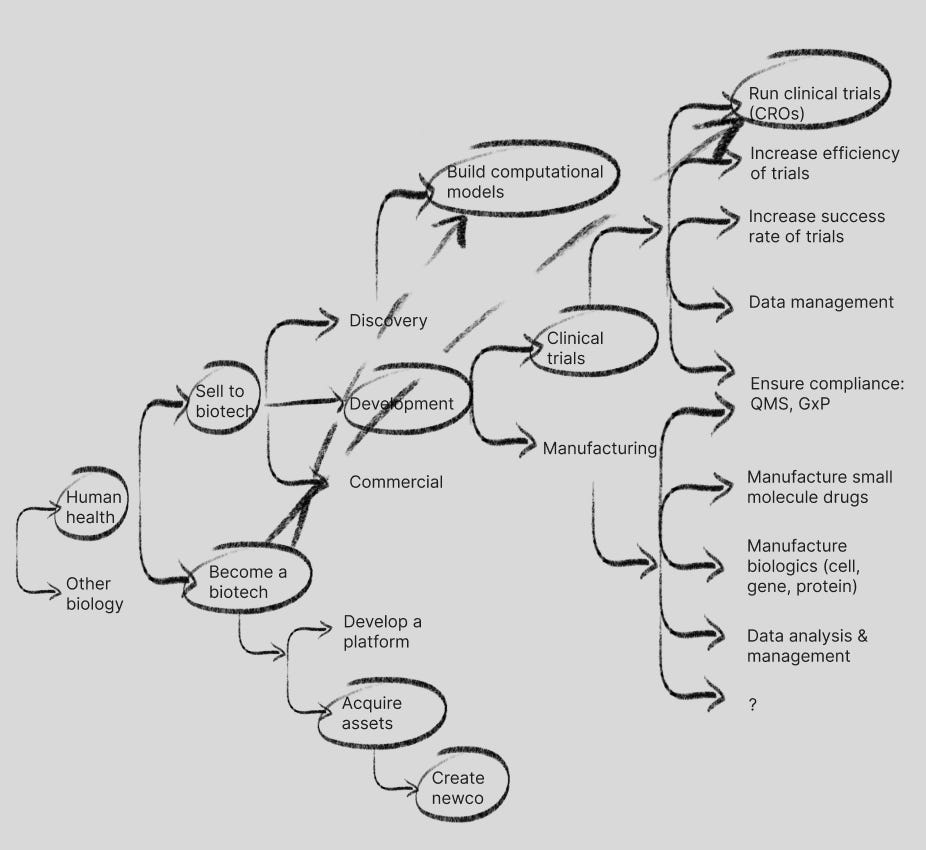
Finally, some more pointed approaches to increasing clinical trial success rate include the creation of digital twins (Unlearn, with OpenAI CTO Mira Murati on the board) to reduce the number of patients required for a given trial, and enrichment drug targets with genetic evidence and deep phenotypic linking for better clinical trial target population selection (Pheiron, disclosure: I’m an investor).
There are other clinical trials needs that TechBio companies address including data management (Dassault Systèmes) and general R&D data platforms (Veeva Vault), along with quality management systems and Good (research, clinical, manufacturing) Practice compliance, however these are not areas I will go into much depth on in this post, as they are not great pivot points in the idea maze; though notably Veeva started on the commercial data / CRM side and has made a nice pivot into R&D data & solutions, which has become the projected top subscription revenue driver for Veeva in 2025.
Manufacturing: small molecule, biologic, and data management/analysis, with lots of white space
Manufacturing is a space that may not have obvious levers for TechBio companies to address, but we are starting to see some attempts to address needs in the space.

Outside of large pharma, contract drug manufacturing organizations (CDMOs) largely execute manufacturing with incumbents including Lonza Group, Thermo Fisher Scientific, Catalent and others, though largely focused on small molecule drugs (chemically synthesized). ElevateBio, Resilience, Kriya Therapeutics are all making bets in gene and cell therapy manufacturing as the new stage of growth for drug development with significant challenges, but Kriya is the only one with its own pipeline effectively dogfooding its own platform.
The data and analytics layer is another opportunity for providing more insight into bioprocess data across various manufacturing use cases, which is an area that Invert is addressing.
There are fewer TechBio companies in manufacturing overall, however that does not mean there is not more white space to explore here, for example in small molecule drug synthesis optimization.
Commercial
Pharma commercial budgets are huge relative to R&D, with spend averaging 25% of revenue. This is a big pot of spend, and there are many needs to serve.

Most of these needs are currently fulfilled by management consulting firms and data providers; I used to be a management consultant in the space focused on pharma commercial strategy so know this space well. To give you a sense of size will be an estimated $18B+ in life sciences consulting spend in 2024. On the data side, there are many needs filled by prescriber data (IQVIA, formerly IMS Health that has a virtual monopoly on this space), patient journey data (also IQVIA, and many others), real world data (many providers including Datavant), diagnostics data (genomics companies like 10x Genomics and Illumina, but also newer ones like Tempus).
The commercial pharma SaaS space has a few players including Veeva, which was first built as a layer on top of Salesforce’s CRM by a former Salesforce executive. As mentioned in a previous section of this post, Veeva has diversified its original commercial solutions with R&D solutions and is a power player in the market and one of the most capital efficient IPOs in TechBio and overall ($7M raised for a $4.4B IPO, current market cap $30B).
Tempus is probably one of the most interesting companies in this group as it has built off its strong foundation in diagnostics and NGS/multiomics analysis of tumor samples to build many business lines including precision medicine clinical workflows and a spin-off oncology drug discovery company called Pathos AI. It is one of the few examples of a commercial-focused TechBio that has acted on aspirations to becoming an AI-native biotech by jumping from finding the right patients to building the computational models and discovering new drugs.

There are some challengers to these incumbents. One interesting one is Convoke (disclosure: I’m an investor) that is using LLMs to replicate a lot of the work that life sciences commercial strategy consultants do, and another is Norstella, a $5B PE rollup of various commercial data operations that crosses data needs for both commercial and development organizations.
AI-native / full-stack biotech as a winning strategy?
So what have we learned? Aside from a variety of starting points in the idea maze to solve needs for various functions of a biotech, maybe the ultimate destination of all of TechBio is to become AI-native or full-stack biotech. We’ve seen this with Schrödinger, Recursion and the band of AI drug discovery companies they have inspired, Vial and Formation Bio starting in clinical development, and Tempus starting in commercial diagnostics:
Benchling and R&D data platform / cloud providers have largely bucked the trend of becoming a full-stack / AI-native biotech, and are moving towards expansion beyond the life sciences industry to the “other biology” branch of the idea maze.

As mentioned in my previous post, the full-stack startup approach seems to be the path that many digital health startups took to avoid having to convince other healthcare companies to buy their software. It was a winning formula with full-stack primary care (One Medical, Oak Street Health both selling for 4-5x TTM revenue), though less so for full-stack insurance (Oscar and Clover Health trading at 0.5-0.6x TTM revenue).
My bet is that the initial winning AI-native biotech strategies will be TechBio startups starting on the development side given the inherent bottleneck that clinical trials pose to drug approval, but I wouldn’t be surprised if we see TechBio’s that started in the manufacturing and commercial space emerge as successful AI-native biotech strategies as well. AI-native biotechs originating from TechBios in drug discovery may lead to early wins for the first one to get an approved drug, but may also result in traditional biopharma companies replicating AI drug discovery models and incorporating into their R&D strategy. What do you think?